ZookeeperServer是一个简单的单机的实现。请求处理链为:PrepRequestProcessor -> SyncRequestProcessor -> FinalRequestProcessor
看一下ZooKeeperServer的启动流程,ZooKeeperServer的启动是在ServerCnxnFactory中进行的
在NIOServerCnxnFactory.startup方法中
1 |
|
startdata是恢复本地数据,每次在zookeeper启动的时候都需要从本地快照数据文件和事务文件中进行数据恢复startup启动zkServer
恢复数据
1 |
|
从上面对的代码中可以看到,主要分为loadData三步:
- 加载数据库,设置zxid
- 清理过期session
- 生成一个快照
逐步研究
加载数据库
时序如下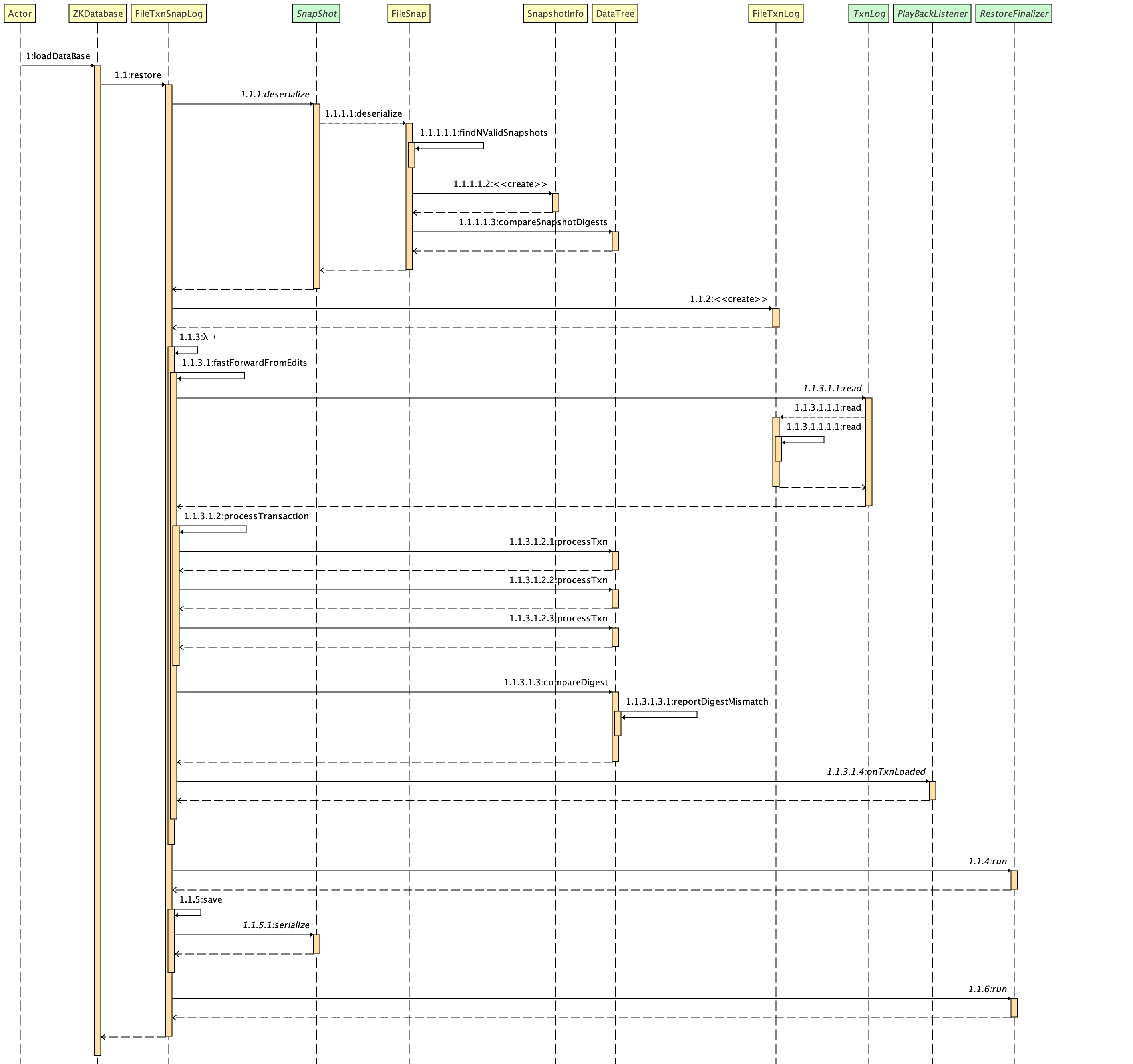
可以看到,ZKDataBase.loadDataBase是通过FileTxnSnapLog提供的能力实现的,前面也说过,FileTxnSnapLog是zk中的数据管理器,是用来操作事务日志和快照的工具类。
1.1.1 deserialize 快照恢复
1 | public long deserialize(DataTree dt, Map<Long, Integer> sessions) throws IOException { |
- 第5行,
findNValidSnapshots是用来查找100个合法的且最近的快照文件 - 第15行,根据快照名称解析出zxid
- 第18行,反序列化快照,将反序列化处的session数据和节点数据分别填充到sessions和dt中
- 第31行,虽然查询的是最近的100个快照文件,但是可以看到当找到一个最新的合法的快照后,就不会再继续往下了,也就是说只有在最新的快照不可用时,才会使用历史快照恢复
- 第40、41行,记录最后的zxid
经过上面的快照恢复,zk中已经存在一份近乎全量的数据了,下面就要通过快照对数据进行增量恢复
1.1.3.1 fastForwardFromEdits 事务日志恢复
1 | public long fastForwardFromEdits( |
- 第5行,从快照恢复的zxid+1,开始读取事务日志
- 第25行,根据事务日志恢复数据
数据恢复到此结束,下一步启动zkServer
启动zkServer
1 | private void startupWithServerState(State state) { |
- 第3行,创建
sessionTracker - 第5行,启动
sessionTracker - 第6行,设置请求处理器
RequestProcessor - 第8行,启动请求节流器
RequestThrottler - 第16行,设置状态
请求处理
在前面的NIOServerCnxn的doIO调用链中,可以看到实际上请求是交给zkServer处理的
连接请求处理
ZooKeeperServer.processConnectRequest方法处理连接请求
- 对于新连接请求: 会创建session,并将封装请求为
Request对象,交给RequestThrottler处理 - 对于重连的请求: 会对session进行校验,通过后重新打开session
其他请求处理
ZooKeeperServer.processPacket方法处理连接请求
RequestThrottler 请求限流器
RequestThrottler会限制当前提交到请求处理器管道的未完成的请求数量。RequestThrottler是如何实现限流功能的呢?
RequestThrottler内部会维护一个队列submittedRequests,当zkServer调用RequestThrottler.submitRequest()时,RequestThrottler会现将请求放到队列submittedRequests中。RequestThrottler又是ZooKeeperCriticalThread的子类,所以在调用其start方法时,实际上是启动了一个线程,这个线程会执行RequestThrottler.run()方法,在run方法中,RequestThrottler通过不断的比较zkServer正在处理的请求数量和最大允许的请求数量,判断是等待还是立即提交给zkServer处理。
通过submittedRequests加一个受控的消费队列的线程,就实现了限流器的功能
看一下细节
配置项
zookeeper.request_throttle_max_requests-maxRequests:
The total number of outstanding requests allowed before the RequestThrottler starts stalling. When set to 0, throttling is disabled. The default is 0.允许在zkServer中未完成的请求数量(即不做限流的请求数),如果设置为0,即不开启限流功能,默认为0zookeeper.request_throttle_stall_time-stallTime:
The maximum time (in milliseconds) for which a thread may wait to be notified that it may proceed processing a request. The default is 100.请求等待线程处理的最大时间,其实就是在一个循环中线程的休眠时间,等会看代码就知道了。request_throttle_drop_stale-dropStaleRequests:
When enabled, the throttler will drop stale requests rather than issue them to the request pipeline. A stale request is a request sent by a connection that is now closed, and/or a request that will have a request latency higher than the sessionTimeout. The default is true.如果开启这个配置,限流器将会直接丢弃超时的请求,而不是交给请求处理器处理。默认是开启。zookeeper.throttled_op_wait_time-throttledOpWaitTime: 这个配置是一个ZooKeeperServer的配置,后面说
具体实现
看一下run方法的代码
1 |
|
- 第9行,从队列中取出一个请求,队列先进先出,所以是按照请求的到达顺序处理的
- 第19行,通过配置
maxRequests的值,判断是否开启了限流功能,如果开启了,会进入下面的while循环 - 第21行,通过配置
dropStaleRequests判断是否开启了超时自动自动丢弃,通过request.isStale()判断该请求是否已经超时,如果满足这两个条件,就会将超时的请求直接处理掉 - 第46行,判断请求在
RequestThrottler中的耗时,是否超过了请求标记的限流耗时,如果超过了的话,FinalProcessor处理器就会返回一个错误相应(错误码ZTHROTTLEDOP),并且会将该请求标记为限流超时,即setIsThrottled为true - 第50行,将请求提交给
zkServer处理,zkServer.submitRequestNow()中,会更新请求的session过期时间,校验请求类型,然后将请求提交给请求处理链的第一个请求处理器处理。
RequestProcessor 请求处理器
zkServer的请求处理器是在setupRequestProcessors中初始化并启动的
1 | protected void setupRequestProcessors() { |
处理器链:(PrepRequestProcessor) firstProcessor
=> (SyncRequestProcessor) syncProcessor
=> (FinalRequestProcessor) finalProcessor
处理器链类似于javax.servlet.Filter的设计,也是一种链式调动,这种设计模式,叫做责任链
看一下上面三种处理器的继承关系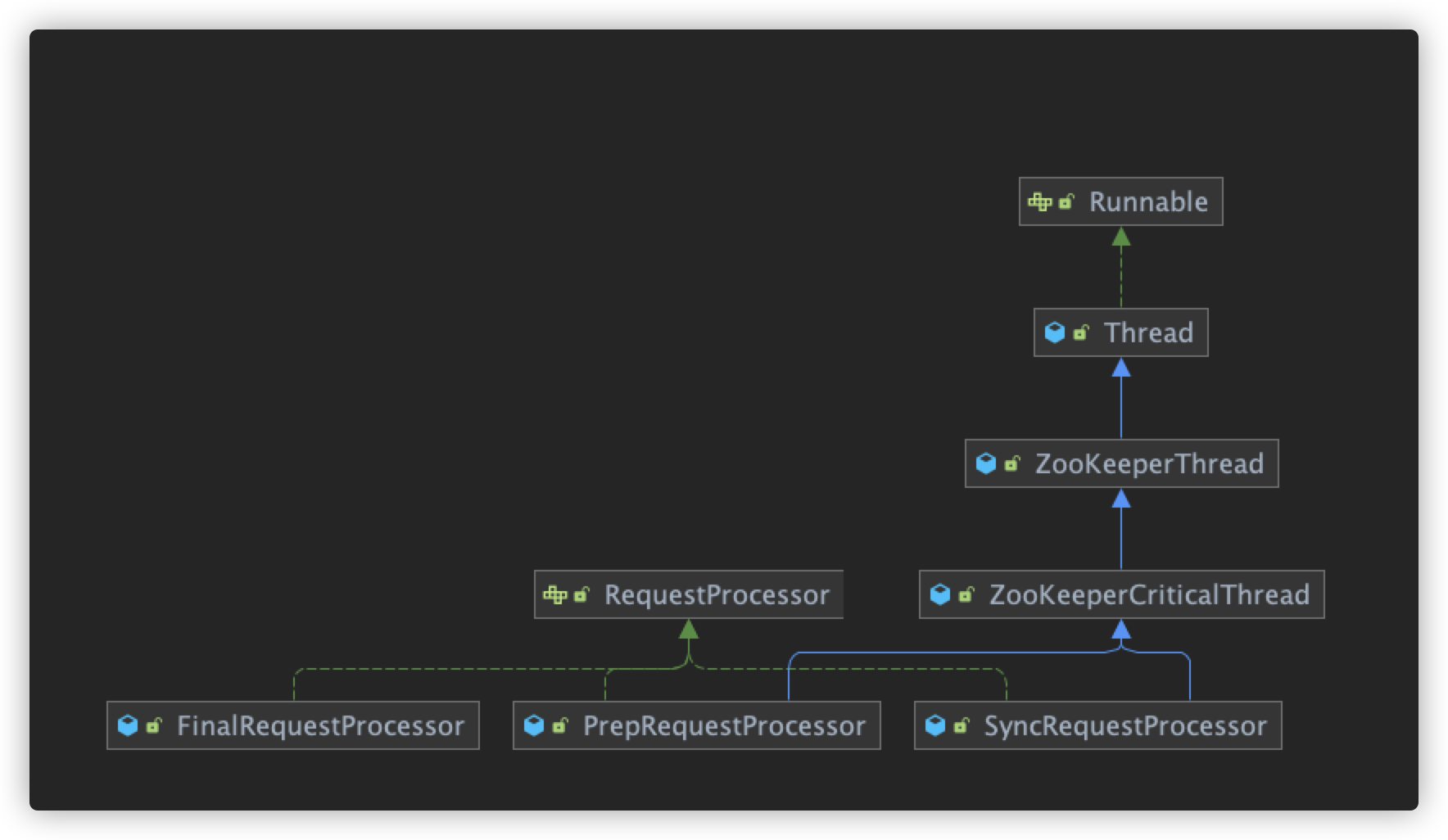
可以看到PrepRequestProcessor和SyncRequestProcessor都是Thread
的子类,因为当调用它们的start方法时,都会启动一个线程
再看一下RequestProcessor接口
RequestProcessors are chained together to process transactions. Requests are always processed in order. The standalone server, follower, and leader all have slightly different RequestProcessors chained together. Requests always move forward through the chain of RequestProcessors. Requests are passed to a RequestProcessor through processRequest(). Generally method will always be invoked by a single thread. When shutdown is called, the request RequestProcessor should also shutdown any RequestProcessors that it is connected to.
意思就是说,多个请求处理器以链式处理事务。按顺序处理。单机、follower、leader都有不同的请求处理器链。请求通过RequestProcessor的processRequest()方法在处理器链中传递。通常,这个方法都是被单线程调用。当调用shutdown时,链中的其他RequestProcessor也应当shutdown。
该接口只定义了两个方法:
1 | void processRequest(Request request) throws RequestProcessorException; |
与文档中描述的一致processRequest的入参就是Request,用来接收需要处理的请求
PrepRequestProcessor
从前面可以知道
PrepRequestProcessor实际上是Thread的子类
所以当调用其start方法时,会启动一个线程查看
PrepRequestProcessor的processRequest方法的代码,可以看到,该方法内并没有直接处理,而是先将请求存放到队列submittedRequests中PrepRequestProcessor的run方法会从队列submittedRequests中取出待处理的请求进行处理
看下run的代码
1 |
|
- 第7行,从
submittedRequests队列中取出请求 - 第22行,调用
pRequest处理
pRequest代码
1 | protected void pRequest(Request request) throws RequestProcessorException { |
- 第7行,如果请求没有被标记为限流超时,会调用
pRequestHelper处理,对于事务请求,在pRequestHelper方法中,PrepRequestProcessor会为事务请求创建事务头、事务体,对于非事务请求,PrepRequestProcessor会进行checkSession操作 - 第14行,交给下一个处理器处理
SyncRequestProcessor
看一下javadoc
This RequestProcessor logs requests to disk. It batches the requests to do the io efficiently. The request is not passed to the next RequestProcessor until its log has been synced to disk. SyncRequestProcessor is used in 3 different cases 1. Leader - Sync request to disk and forward it to AckRequestProcessor which send ack back to itself. 2. Follower - Sync request to disk and forward request to SendAckRequestProcessor which send the packets to leader. SendAckRequestProcessor is flushable which allow us to force push packets to leader. 3. Observer - Sync committed request to disk (received as INFORM packet). It never send ack back to the leader, so the nextProcessor will be null. This change the semantic of txnlog on the observer since it only contains committed txns.
意思就说,这个SyncRequestProcessor请求处理器会将请求记录到磁盘。会进行批量处理以便高效地执行IO操作。在将日志同步到磁盘之前,不会将请求交给下一个处理器。SyncRequestProcessor有3个不通的使用场景:
- Leader - 将请求同步到磁盘并转发给
AckRequestProcessor,后者将ack发送给自身 - Follower - 将请求同步到磁盘,并将请求转发给
SendAckRequestProcessor,后者将数据包发送给leader。 - Observer - 将提交的请求同步到磁盘
从上面的文档介绍中可以知晓SyncRequestProcessor的主要作用是将请求同步到磁盘,对请求进行持久化,然后再转发给下一个处理器处理。
SyncRequestProcessor内部维护了两个队列:
queuedRequests: 新的请求提交到SyncRequestProcessor时,不会直接处理,而是先进入queuedRequests队列,等待处理。当调用SyncRequestProcessor.shutdown()方法时,也不会立即就停掉,而是往queuedRequests队列中添加一个特殊的请求REQUEST_OF_DEATH,当SyncRequestProcessor从队列queuedRequests消费到REQUEST_OF_DEATH请求后,就会退出toFlush:SyncRequestProcessor将从队列queuedRequests中获取到请求后,会先记录事务日志,然后将请求添加到toFlush队列,后续经过一些条件判断后,再将toFlush队列中的请求提交给下一个请求处理器
还有一点需要注意,javadoc中所说的持久化到磁盘,其实包含两类操作:
- 记录事务日志: 从
queuedRequests中消费的每个请求(事务请求)都会先记录事务日志,然后进入到toFlush队列 - 快照: 事务日志记录完成后,会判断是否需要进行快照操作,如果需要进行快照,会单独启动一个线程进行快照操作
看一下源码实现
run方法
1 |
|
- 第6行,从代码注释上可以看到,但是还不是很清晰,后面研究
- 第12行,尝试从队列中超时获取请求,如果没有取到,就先进行
flush操作,再阻塞式获取 - 第19行,如果取出的请求是
REQUEST_OF_DEATH,跳出循环,线程结束 - 第27行,如果请求没有限流超时标记,并且事务日志记录成功,就开始判断是否需要进行快照
- 第33行,先尝试获取一个快照锁,获取成功后单独创建一个新的线程来负责快照
- 第49行,如果取出的请求被标记为限流超时、或者请求是一个读请求,并且
toFlush队列为空,就直接交给下一个处理器处理 - 第61行,将请求添加到
toFlush队列 - 第62行,判断是否需要进行
flush操作
记录事务日志的时候,调用的是
ZKDatabase.append(Request)方法,这个方法的会记录事务日志,并且会用一个变量txnCount记录事务的数量,但是查源码会发现,ZKDatabase.append(Request)只有在请求是事务请求时才会记录,返回成功,否则返回失败,但txnCount却没有判断请求是否为事务请求,也就是说不论请求是事务的还是非事务的txnCount都会记录。我看了这个段代码之后,觉得可能有问题,已经提了issue,https://github.com/apache/zookeeper/pull/1744
FinalRequestProcessor
javadoc
1 | This Request processor actually applies any transaction associated with a request and services any queries. It is always at the end of a RequestProcessor chain (hence the name), so it does not have a nextProcessor member. This RequestProcessor counts on ZooKeeperServer to populate the outstandingRequests member of ZooKeeperServer. |
从文档介绍,可以得出,FinalRequestProcessor的作用和特点:
- 是将事务请求应用到数据库的处理器
- 是实际执行查询的处理器
- 位于处理器链的最后一个,没有
nextProcessor - 最后一句没看懂,依赖ZooKeeperServer来传递未完成的请求??
代码太多就不贴了,正如文档所说,FinalRequestProcessor所做的事情如下:
applyRequest,将请求交给zkServer处理,包含事务请求和查询请求,记录处理的返回结果- 将
zkServer中正在处理的请求减1 - 构建响应体、响应头
- 响应交给
ServerCnxn处理
RequestProcessor就说到这里,下面看一下ZooKeeperServer中另一个比较重要的类
总结
ZooKeeper服务器启动期间,首先会进行数据初始化工作,即根据本地的快照和事务日志恢复本地数据。然后会启动内部组件,例如限流器、会话跟踪器、请求处理器等。
ZooKeeperServer处理请求的流向是: ServerCnxn => ZooKeeperServer => RequestThrottler => PrepRequestProcessor => SyncRequestProcessor => FinalRequestProcessor
ServerCnxn可以理解为一些额外信息的客户端socketZooKeeperServer扮演一个请求处理者,内部有限流、处理器管道等设计RequestThrottler是一个限流器PrepRequestProcessor主要负责队请求进行前置处理,例如为事务请求添加事务头、事务体等SyncRequestProcessor负责记录事务日志、选择时机进行快照FinalRequestProcessor负责将请求进行真正的应用,构建相应,并返回客户端
RequestProcessor的设计使用的是责任链模式,链中的每个节点负责处理自己的事务,各个节点各司其职,功能划分清晰。